The Test Is Now the Gate
Coding agents are flooding release pipelines with code no one can fully review. Discover why automated testing is now your only real quality gate.

Your reviewers are looking at PRs three times the size they were a year ago. The merge queue isn't slowing down to accommodate them, and the coding agents opening those PRs aren't either.
Faros AI's telemetry across 10,000+ developers puts numbers on what most SDETs already feel: AI coding assistants increase PR size by over 50%, and median review time has climbed more than 400% (Faros AI, 2025). Review queues that used to be manageable have become a structural problem.
The teams that have noticed are reorganizing around a different gate. Code review still happens, still gets logged, still shows up in the workflow. But the actual decision about whether AI-generated code is safe to merge is being made by the test suite, because that's the only check left that scales with how fast agents are producing code.
Why Manual Review Can't Save You Anymore
Manual code review was never built to handle quality checks at today’s scale. It worked when humans wrote the code, reviewed it, and kept the batch size manageable. But that world is gone, because AI coding agents now create much larger flows of code.
Research found that only 28.7% of AI coding agent suggestions work without changes (MSR '26, 2026). The quality also varies significantly with task complexity (MSR '26, 2026). So, most AI-generated changes still need careful review before they can be trusted.
Many of these changes still look clean when reviewers first see them. They may compile, pass static checks, and solve the problem in front of them. But they can still break patterns that teams have built and protected for years.
This makes reviewers the last line of defense against risks that are hard to see in full. The pressure increases when many coding agents run simultaneously. Human-paced pipelines can also cancel out the gains that led teams to adopt AI (DORA, 2025).
Test Coverage Has Become the Real Approval Mechanism
Something has quietly changed in how teams approve releases. Whether teams admit it or not, passing tests now often decides if AI-generated code gets merged. At this scale, teams simply do not have another reliable signal.
This shift has serious consequences for software quality. If your test suite is shallow, your approval gate is too. If your tests are brittle or flaky, then your gate becomes noise.And if coverage hasn't kept up with the code agents are producing, large portions of every release are passing through unchecked, regardless of how green the pipeline looks.
The World Quality Report 2025–26 found the average automation coverage across organizations sits at 33% (World Quality Report, 2025–26). That number was already a problem when developers were writing code at human pace. At agent pace, it means roughly two-thirds of every release is being approved by something other than the test suite, which in practice means it isn't being approved at all.
Passing unit tests does not mean the whole system works. But when each release changes hundreds of files, unit tests often become the only check before production. The real question is whether your test infrastructure is ready to carry that weight.
The QA Practitioner's Impossible Position
QA practitioners now carry more responsibility when their old methods are least prepared for the work. This is not abstract; it is the daily reality for testers on teams using coding agents. The World Quality Report 2025–26 found 43% of organizations are testing generative AI in QA, but only 15% have scaled it enterprise-wide (Capgemini/Sogeti, 2025–26).
For the practitioner in the middle, this creates three compounding pressures:
- Volume pressure: More code is landing per sprint than any script-based regression suite was built to handle. Backlogs grow faster than test scripts can be updated.
- Coverage pressure: Change surface area now includes files that weren't on anyone's regression list. Every release has blind spots that didn't exist in the previous one.
- Maintenance pressure: Script-based test suites break when code changes rapidly. The time testers spend fixing broken tests is time they aren't spending on new coverage.
The practitioners who are struggling are not failing because they lack skill. They are failing because the tooling they were given was designed for a slower, smaller, more predictable world.
Why Script-Based Regression Breaks at Agent Velocity
Script-based test automation was built on one simple idea: code changes slowly, and humans write both code and tests. That idea no longer works when agents rewrite large parts of a system in a single PR. When a module changes across 30 files, old test scripts can break silently, leading to false passes.
The brittleness problem is structural, not incidental. Consider what happens at agent velocity across three common failure modes:
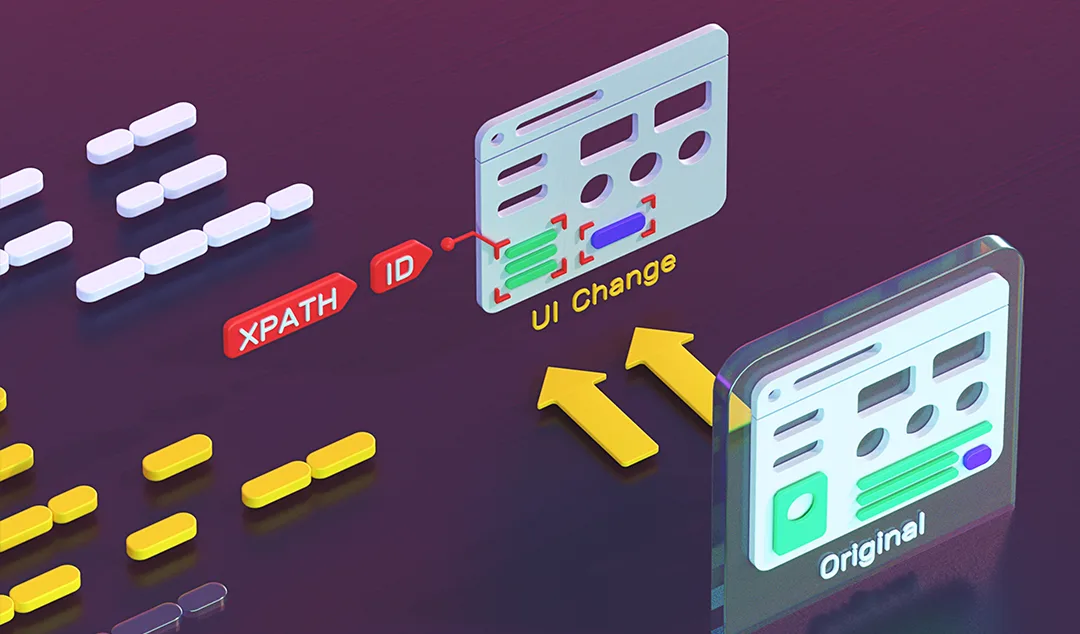
Selector Drift
Agent-generated UI changes often rename elements, reshape DOM structures, and move component boundaries. Tests built on CSS selectors or XPath references can break quickly, sometimes without clear failures. With each sprint, testers spend more time fixing old tests than writing useful new ones.
Logic Drift
Agents often focus on making tests pass rather than protecting the behavior behind those tests. A calculation test may pass after an agent refactor, while edge cases now round differently. The gate passes, but the bug still reaches production.
Coverage Drift
As agent contributions grow, codebases, new modules and interaction paths appear quickly. Existing test suites often do not expect these new paths or cover them well. Coverage metrics may remain steady while the actual share of tested behavior continues to fall.
The Data Behind the Quality Crisis
The numbers are clear across several research sources. AI coding tools increase output speed, but they can weaken quality signals. This happens unless testing systems are built to handle the extra pressure.
CodeRabbit found that AI-assisted code creates 1.7x more logical and correctness bugs (CodeRabbit, 2026). These bugs are more serious than simple style or formatting issues. They can affect how the software behaves after release.
Another study found velocity gains of up to 281% with AI coding agents. But those gains fell back to baseline by the third month. Static analysis warnings also stayed 30% higher and did not resolve themselves (MSR '26, 2026).
The 2025 DORA report adds another concern. Nearly 40% of organizations have a change failure rate above 16% (DORA, 2025). At agent speed, that means broken releases become likely, not rare.
Agentic Testing Is the Logical Response
The answer to an agent-speed quality crisis is not more manual work or faster script writing. The only response that scales is testing agents that match coding agents in speed and application understanding. This is already happening in teams that understand how much the development process has changed.
What agentic testing looks like in practice is distinct from what most teams think of as AI-enhanced testing:
Understanding the Application, Not Just the UI
Agentic testing tools work at the application level, so they understand intent, business logic, and user flows. They can create and maintain tests that survive code changes without breaking when selectors change. Instead of testing today’s implementation, they test what the application is meant to do.
Maintaining Context Across the Release Cycle
A testing agent with a long-term application context can see what changed in each new release. It does not start from scratch with every PR, because it remembers earlier coverage. It connects agent-generated changes with the tests that already existed before those changes arrived.
Scaling With Development Velocity
Script-based regression suites become a bottleneck when code volume grows quickly. Agentic testing can scale in the same direction as the development team’s output. More code does not create more maintenance work; it creates smarter coverage for the highest-risk areas.
The Bottom Line: If Agents Write the Code, Agents Need to Validate It
The quality crisis created by coding agents is not going away. It will grow as agentic development becomes normal across software teams. Teams that fail to close the testing gap will ship broken releases faster.

Practitioners did not create this problem, but they are being asked to solve it. They are also being given tools that were not built for agent-speed development. The key shift is simple: the test is now the gate.
Testing is no longer just a checkpoint at the end of development. It is how quality is either enforced or quietly bypassed. Functionize gives teams a testing agent that understands applications and keeps context across releases.
Ready to see what agentic QA looks like at the velocity your team is already moving at? Book a personalized demo or start a free trial.









